초 간단 논문리뷰 | Phraseformer: Multimodal Key-phrase Extraction using Transformer and Graph Embedding
- ref
- Article: https://arxiv.org/pdf/2106.04939.pdf (2021)
- code 없음
Keywords: Multimodal representation learning, Keyword extraction, Transformer, Graph embedding, (Key-phrase extraction)
Models: Bert(Transformer) & ExEm(Graph Embedding) → Random Forest Metric: F1-score

의견
논리적으로 좋은 아이디어인듯!
- text embedding, node(structure) embedding 두 모델의 앙상블
- random forest로 BIO tagging classification (with f-1 score)
단,
- code가 없어 당장 써보기 어려움 (ExEm 대신 node2vec 사용해봐도 될듯)
- 다만, 우선 구조적으로 graphical dataset을 만들어?찾아?야하지 않나? and 우리의 데이터셋은 structure(relationship)를 배울 필요성이 있나? 고민해보기
“Its size is ideal and the weight is acceptable.”
Attention-based models often identify acceptable as a descriptor of the aspect size, which is in fact not the case.

→ sentences as dependency graphs로?→ 생성을 어떻게 하지? → en의 경우 parser 있음
* graphs neural net의 장점: un( or semi)supervised learning, unkown relation(edge) embedding 가능
⇒ 사용할만한 keyphrase idea: BERT-RandomForest(BIO tagging)
Abstract
1. Background
Keywords are terms that describe the most relevant information in a document.
However, previous keyword extraction approaches have utilized the text and graph features, there is the lack of models that can properly learn and combine these features in a best way.
2. Methods
In Phraseformer, each keyword candidate is presented by a vector which is the concatenation of the text and structure learning representations.
Phraseformer takes the advantages of recent researches such as BERT(Sentence Embedding) and ExEm(Graph Embedding) to preserve both representations.
Also, the Phraseformer treats the key-phrase extraction task as a sequence labeling problem solved using classification task.
3. Results
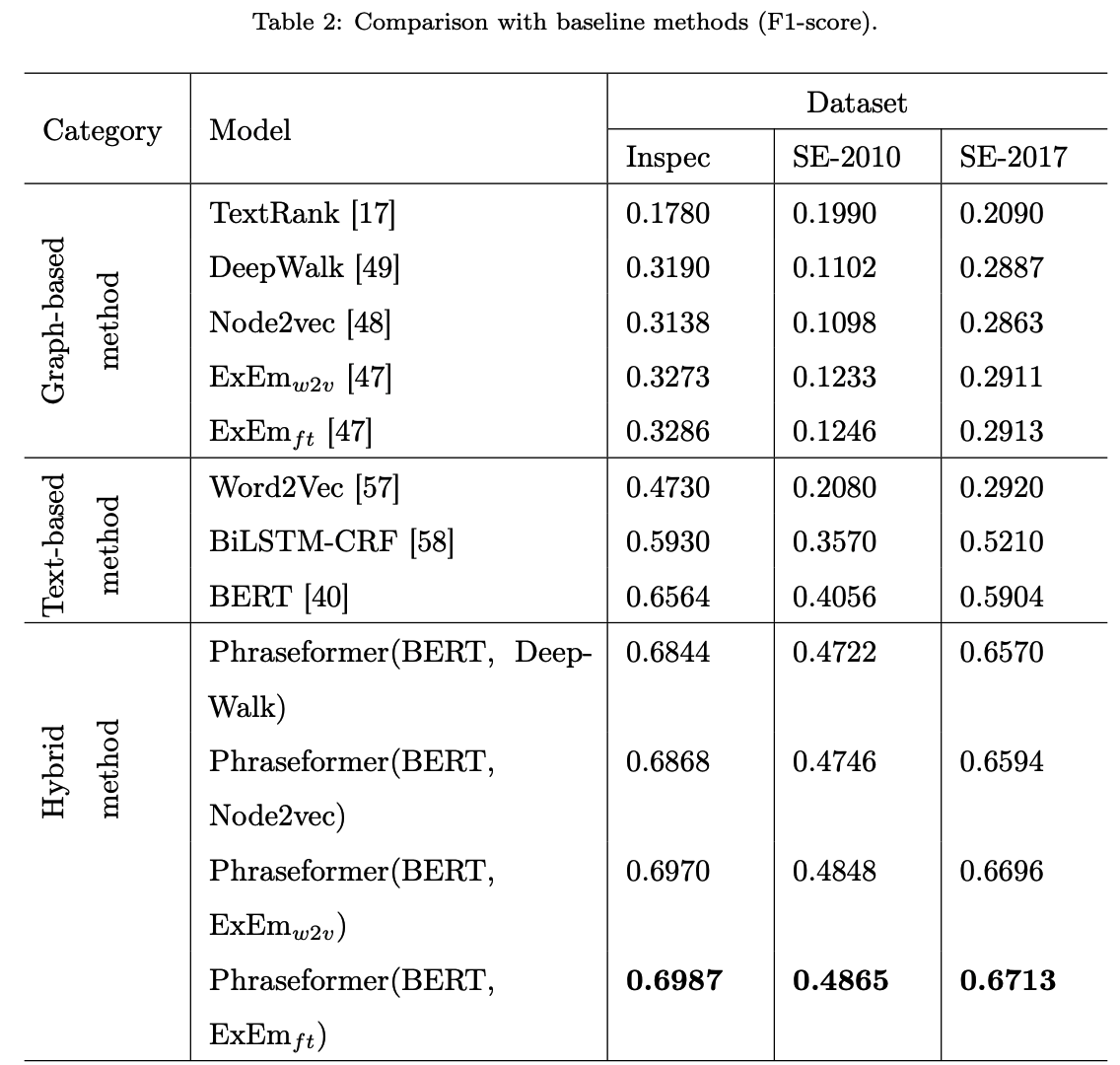
F1-score, three datasets(Inspec dataset, ..) used
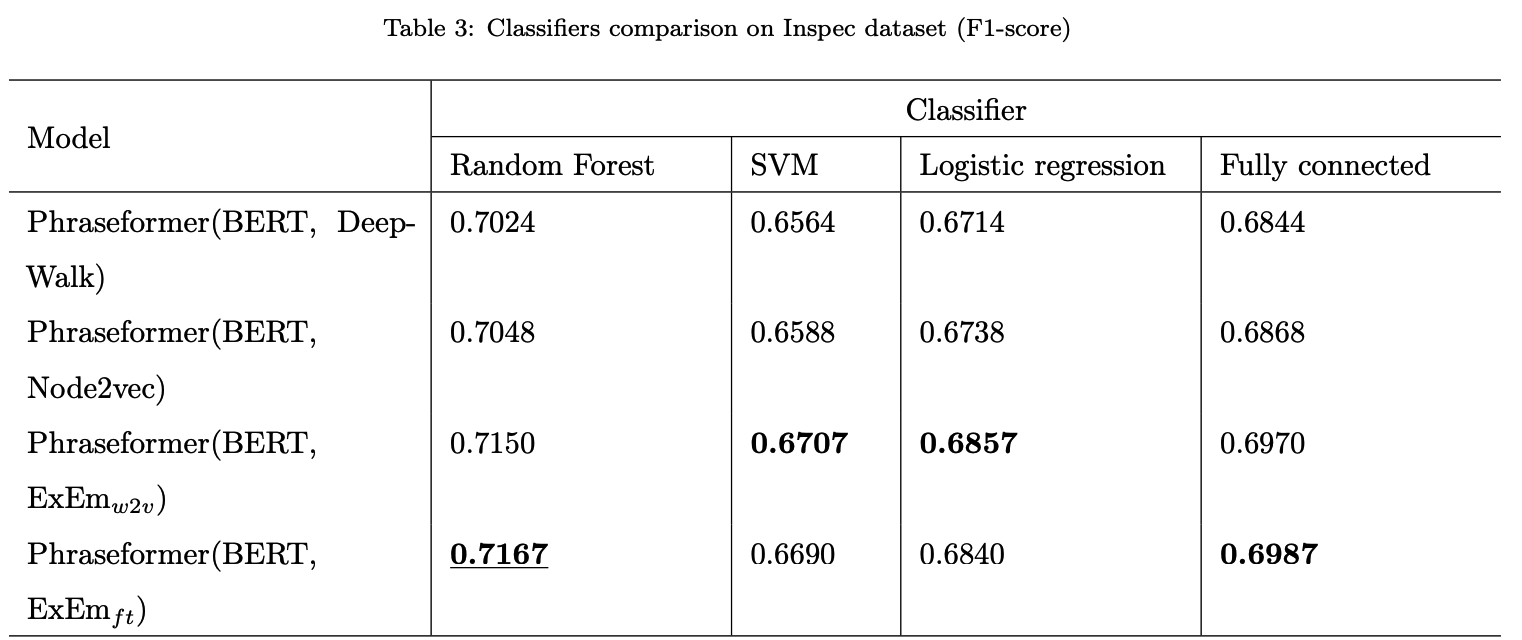
Additionally, the Random Forest classifier gain the highest F1-score among all classifiers.
4. Conclusions
Due to the fact that the combination of BERT and ExEm is more meaningful and can better represent the semantic of words.
Experimental Evaluation & Results
1. Dataset
Inspec includes abstracts of papers from Computer Science collected between the years 1998 and 2002. SE-2010 contains of full scientific articles that are obtained from the ACM Digital Library. In our experiment, we used the abstract of papers. SE-2017 consists of paragraphs selected from 500 ScienceDirect journal papers from Computer Science, Material Sciences and Physics domains.

*Gold keys: the ground-truth keywords
2. Metrics
$\text{F1-score} = 2 \times \frac{\frac{Y\cap Y'}{Y'}\times \frac{Y\cap Y'}{Y}}{\frac{Y\cap Y'}{Y'} + \frac{Y\cap Y'}{Y}} = 2\times \frac{\text{precision}\times\text{recall}}{\text{precision}+\text{recall}}$
$\text{precision} = \frac{\text{number of correctly matched}}{\text{total number of extracted}} = \frac{TP}{TP+FP}$
$\text{recall} = \frac{\text{number of correctly matched}}{\text{total number of assigned}} = \frac{TP}{TP+FN}$
3. Baseline models
Node2vec [48] is modified version of DeepWalk that uses a biased random walks to convert nodes into vectors.
- We propose node2vec, an efficient scalable algorithm for feature learning in networks that efficiently optimizes a novel network-aware, neighborhood preserving objective using SGD.
- We extend node2vec and other feature learning methods based on neighborhood preserving objectives, from nodes to pairs of nodes for edge-based prediction tasks.
ExEm [47] is a random walk based approach that uses dominating set theory to generate random walks.
- Article: https://arxiv.org/abs/2001.08503
- official code: https://github.com/AzarKh/ExEm…?
- A novel graph embedding using dominating-set theory and deep learning is proposed.
- $ExEm_{ft}$ : It is a version of ExEm that engages fastText method to learn the node representation.
- $ExEm_{w2v}$: This one is another form of ExEm that allows to create node representations by using Word2vec approach.
BERT [40] is a textual approach that uses the transformer structure to obtain the document representation.
- Article: https://arxiv.org/abs/1810.04805
- official code: https://github.com/google-research/bert
4. Classifier (BIO tagging)
In this part of our experiment we aim to investigate which classifier is best suited for sequence labelling and classification tasks to find key-phrases.