Python으로 딥러닝하기| Generative Model & GAN
1. Generative Model 이란
판별모델링 vs 생성모델링
- 판별모델링: sample x가 주어졌을 때 레이블 y의 확률 $p(y|x)$를 추정
- 생성모델링: sample x의 관측확률 $p(x)$를 추정, supervised learning의 경우 확률 $p(x|y)$를 추정
→ Goal: sample로 모델을 훈련 (distribution) → sample에 있을 법한 x 생성하기

generative model은 데이터 범주의 분포를, disciriminative model은 결정경계를 학습한다.

generative model은 사후확률을 간접적으로, disciriminative model은 직접적으로 도출한다.
기존 확률적 생성 모델의 난관
- 특성 간에 조건부 의존성이 매우 클 때 어떻게 대처할 것인가?
- 모델이 어떻게 고차원 표본 공간의 생성 가능한 샘플 중 만족할만한 하나를 찾을 것인가?
전통적인 확률생성모델은 하나의 확률분포 표현식 $P(X)$를 정의해야하는데, 일반적으로 다변량 결합확률분포의 밀도함수 $p(X_1,X_2,\cdots, X_N)$이며, 이에 기반해 likelihood 예측을 최대화한다(MLE).
이 과정에서 확률추론 계산이 빠질 수 없는데, 확률모델은 랜덤변수가 많을 때 매우 복잡해지기 때문에 확률 계산도 매우 어려워진다. 근사 계산을 한다고 하더라도 효과는 만족스럽지 못할 때가 많다.
⇒ Representation Learning (deep learning이 잘하는 것)
: 고차원 표본공간을 직접 모델링 하는 것이 아니라 저차원의 잠재공간(latent vector)을 사용해 훈련 셋의 각 샘플을 표현하고 이를 원본 공간의 포인트에 매핑하는 것
= 잠재공간의 각 포인트는 어떤 고차원 이미지에 대한 representation
2. VAE (AE)
AE (Auto-Encoder)

- 인코더: 고차원 입력데이터를 저차원 representation vector로 압축
- 디코더: 주어진 representation vector를 원본 차원으로 다시 압축을 해제
→ AE는 각 이미지가 잠재공간의 한 포인트에 직접 매핑됨
VAE (Variational Auto-Encoder)
VAE는 각 이미지를 잠재 공간에 있는 포인트 주변의 Multivariate Normal distribution에 매핑
- Encoder
- latent vector ( zero-mean Gaussian )$\sigma = exp(log(var)/2)$
- $\epsilon \sim N(0,1)$
- $z = \mu + \sigma * \epsilon$
- 분산에 log를 취하는 이유: 신경망 유닛의 일반적인 출력은 $(-\infin, \infin)$범위의 모든 실수지만 분산은 항상 양수임
- 평균과 벡터만 매핑하는 이유: VAE는 latent vector의 차원 사이에는 어떠한 상관관계가 없다고 가정함
- Decoder⇒ 계산이 어렵기 때문에 KLD가 줄어드는 쪽으로 $q(z)$를 근사하는 방법으로 적용한다.
- KLDivergence : 두 모델 분포들 간 얼마나 가까운지에 대한 정보 손실량의 기대값 (Symmetry하지 않음)
- $D_{KL}(p||q) = E[log(p_i)-log(q_i)] = \Sigma_i p_i log\frac{p_i}{q_i}$
- $q(z|x)$: 다변량 정규분포로 봄
- encoder가 만든 𝑧를 받아서 원 데이터 𝑥'를 복원: $p(z|x)$
3. GAN
: Generative Model을 훈련시키는 방법 idea

- generator(생성알고리즘): 생성한 데이터를 discriminator가 진짜로 인식하도록 하는 것이 목표
- discriminator(판별알고리즘): generator로 부터 전달된 데이터를 가짜로 인식하도록 하는 것이 목표
→ 두 가지 네트워크가 서로 적대적(Adversarial)인 관계임
- train 구조

- minimax objective function학습의 의미: V(D,G)가 최대가 되도록 학습하는 것은 판별자(D), 최소화되도록 학습하는 것은 생성자(G)

- issue
- 진동하는 loss (= 불안정)
- 유용하지 않은 loss (훈련방법이 기존과 달라서 이해하기 어려운 loss)
- mode collapse
- : 생성자가 판별자를 속일 수 있는 하나의 샘플(=mode)을 찾아내려는 경향이 있음
- hyper parameter (많고, 민감함) → 훈련이 어려움
4. Vision GAN
: GAN을 여러 데이터에 훈련시키는 방법 idea (based Vision Task)
Basic) convonvolution


- Convolition: 필터를 이미지의 일부분과 픽셀끼리 곱한 후 결과를 더하는 것
- filter: 컬러 이미지의 경우 3개의 채널을 가짐, 여러개의 필터를 가짐
- (이미지의 영역과 필터가 비슷할수록 큰 양수가 출력되고 반대일수록 큰 음수가 출력됨)
- stride: 필터가 한 번에 입력 위를 이동하는 크기 → 채널의 수는 늘리고 텐서의 공간 방향 크기를 줄이는 데 사용할 수 있음
- padding:
padding="same"의 경우 입력 데이터를 0으로 패딩하여strides=1일 때 출력의 크기를 입력 크기와 동일하게 만듬
- 필터를 전체 이미지에 대해 왼쪽에서 오른쪽으로 위에서 아래로 이동하면서 합성곱의 출력을 기록
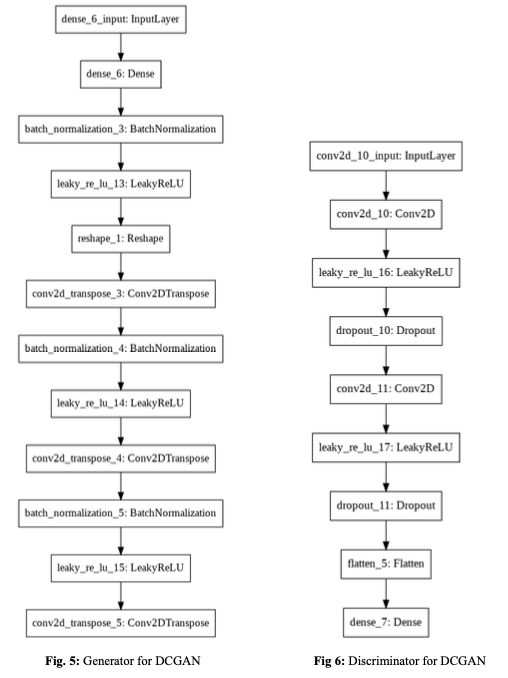
DCGAN
"GANs이 합성곱을 만났을 때!"

CNN은 이미지를 분할하여 화소 위치와 관련된 정보를 대량으로 유실한다. 분류 문제는 잘 해결할 수 있지만 고해상도를 가진 이미지를 출력할 수 없다.
→ Fractional-Strided Convolutions (deconvolutions)
각 층의 높이와 넓이가 줄지 않고 오히려 커져 최종적인 출력과 원래 입력이미지의 크기가 동일할 수 있도록 만들어줌
- Conv_Transpose2D (=deconvolutions)

- 파란 부분: original 이미지
- 이미지 사이에 padding 추가
- filter 통과
- $Output\ Size = (input\ size -1)* stride + 2*padding + (kernel\ size)$
- Architecture guidelines for stable Deep Convolutional GANs
- Fully connected layer와 Pooling layer를 최대한 배제하고 Strided Convolution과 Transposed Convolution으로 네트워크 구조를 만들었습니다. Fully connected layer와 Max-pooling layer는 매개변수의 수를 줄일 수 있지만 이미지의 위치 정보를 잃어 버릴 수 있다는 단점이 있습니다.
- Generator와 Discriminator에 배치 정규화(Batch Nomalization)을 사용하였습니다. 이는 입력 데이터가 치우쳐져 있을 경우의 평균과 분산을 조정해주는 역할을 합니다. 따라서 back propagation을 시행했을 때 각 레이에어 제대로 전달되도록해 학습이 안정적으로 이루어지는데 중요한 역할을 하였습니다.
- 마지막 layer를 제외하고 생성자의 모든 layer에 ReLU activation를 사용하였습니다. 마지막 layer에는 Tanh를 사용하였습니다.
- Discriminator의 모든 레이어에 LeakyReLU를 사용하였습니다.
- Architecture summary
[test image]

CycleGAN

목적: 도메인 A의 이미지를 도메인 B의 이미지로 혹은 그 반대로 바꾸는 모델 훈련하기
- 유효성, 재구성, 동일성의 3박이 잘 이루어져야 훈련이 잘 됨
- 유효성 : 도메인 A의 이미지를 도메인 B의 이미지로 혹은 그 반대로 바꾸기 (기존 GAN loss) → $G_{BA}(b)=fake_a\ or\ G_{AB}(a) = fake_b$
- 재구성(cycle consistency loss) : 도메인 A의 이미지를 도메인 B의 이미지로 또 다시 도메인 A의 이미지로 바꾸기(원래 도메인에 해당하는 이미지로 돌아오는 가?) → $G_{AB}(G_{BA}(b))=reconstr_b \ or \ G_{BA}(G_{AB}(a))=reconstr_a$→ $X$와 $\hat{X}$사이에서 평균 절대 오차 계산
- 동일성(Identity loss) : ( 도메인 A에서 도메인 B으로 Generate하는 모델에 도메인 B 이미지를 넣었을 때 다시 B 도메인의 이미지로 생성을 할 수 있는가? ) $G_{BA}(a)= a \ or\ G_{AB}(b)= b$$Identity\ loss = |G(Y)-Y| + |F(X)-X|$ ⇒ 이미지에서 변환에 필요한 부분 이외에는 바꾸지 않도록 생성자에 제한을 가함
** cycleGAN과 pix2pix의 주된 차이점: 추가 손실 함수(cycle consistency loss)를 사용하여 쌍으로 연결된 데이터없이도 훈련을 할 수 있다. (pair 데이터를 구하기 어려움)
[test image]

5. NLP Generate Model
- 이미지와 텍스트 데이터가 다른 점
- 텍스트 데이터는 개별적인 데이터 조각(문자나 단어)로 구성, 반면 이미지의 픽셀은 연속적인 색상스펙트럼 위의 한 점
- 텍스트 데이터는 시간 차원이 있지만 공간 차원은 없음, 이미지 데이터는 두 개의 공간 차원이 있고 시간 차원은 없음
- 텍스트 데이터는 개별 단위의 작은 변화에도 민감
- 텍스트 데이터는 규칙 기반을 가진 문법 구조
- paper) MODERN METHODS OF TEXT GENERATION (2020)
Basic
- RNN: 시퀀스의 다음 단어 하나를 예측하는 것이 목적
- 기존 단어의 시퀀스를 네트워크에 주입하고 다음 단어를 예측
- 이 단어를 기존 시퀀스에 추가하고 과정을 반복
- Encoder-Decoder (ex, Seq2seq): 입력 시퀀스에 관련된 완전히 다른 단어의 시퀀스를 예측
- 원본 입력 시퀀스는 인코더의 RNN에 의해 하나의 벡터로 요약 → 문맥 벡터(context vector) : 이 벡터는 디코더 RNN의 초깃값으로 사용
- 각 타임스텝에서 디코더 RNN의 은닉 상태는 완전 연결 층에 연결되어 단어 어휘 사전에 대한 확률 분포를 출력(-) 긴 문장의 시작 부분에 정보는 문맥 벡터에 도달할 때 희석될 수 있음
- 언어번역, 질문-대답 생성, 텍스트 요약
- Attention: 인코더의 이전 은닉 상태와 디코더의 현재 은닉 상태를 문맥 벡터 생성을 위한 덧셈 가중치로 변환하는 일련의 층
Transformer (Attention Is All You Need)
AutoEncoder-Decoder 구조 (Seq2Seq 유사)
(개인적인 생각) GAN과 유사한 방법은 Electra or GPT
Elactra paper: https://arxiv.org/pdf/2003.10555.pdf

6. Multi-modal GAN
Zero-Shot Text-to-Image Generation [DALL*E]
- paper) zero-shot text-to-image generation (2021)
- 참고
reference
(book) 미술관에 GAN 딥러닝 실전 프로젝트