Python으로 딥러닝하기|자연어 처리 1. 토크나이징
Python으로 딥러닝하기|자연어 2. 단어 임베딩, Word2Vec
Python으로 딥러닝하기|RNN(Recurrent Neural Networks) Part1. 이론
Python으로 딥러닝하기|LSTM(RNN) Part1&2. 이론 및 실습
Python으로 딥러닝하기|자연어 3. Seq2Seq, Attention
Python으로 딥러닝하기|자연어 3. Seq2Seq, Attention
Python으로 딥러닝하기|자연어 처리 1. 토크나이징 Python으로 딥러닝하기|자연어 2. 단어 임베딩, Word2Vec Python으로 딥러닝하기|RNN(Recurrent Neural Networks) Part1. 이론 Python으로 딥러닝하기|LSTM(RNN) Part1&2.
everyday-deeplearning.tistory.com
오늘은 Transformer에 대해 정리해보겠습니다.
Transformer paper: Attention Is All You Need
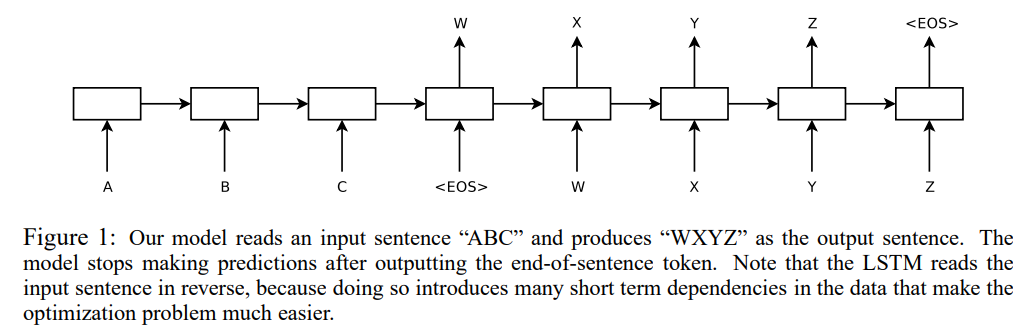
Transformer의 구조는 기본적으로 Seq2Seq의 Encoder와 Decoder 구조를 갖고 있지만, 다른 점은 RNN 대신 Attention Attention 구조'만'으로 전체 모델을 구성하였습니다.

Encoder와 Decoder 각각에서는 Self-Attention 방법을 사용하는데 Seq2Seq과 함께 활용한 기존의 Attention 방법으로는 Encoder의 모든 단어와 Decoder의 단어 사이의 관계를 측정하는 방법이었다면, Self-Attention이란 문장 안에서 각 단어들 간의 관계를 측정하는 방법입니다. (참고로 Encoder와 Decoder 사이의 Attention은 Self-Attention이 아닙니다.)
또한 Multi-head Attention 방법을 통해 한 번에 병렬로 Attention을 수행하는 방법을 사용하였습니다. 각 head 별로 다른 Weight를 사용하여 연산을 수행한 후 concat하는 방식으로 한 번에 다양한 시각의 정보를 학습할 수 있다는 장점이 있습니다. 또한 Attention 하나만 사용할 경우 문장이 길어지면 softmax를 통과한 결과가 0에 가까워져 무의미한 결과를 도출할 수 있습니다.
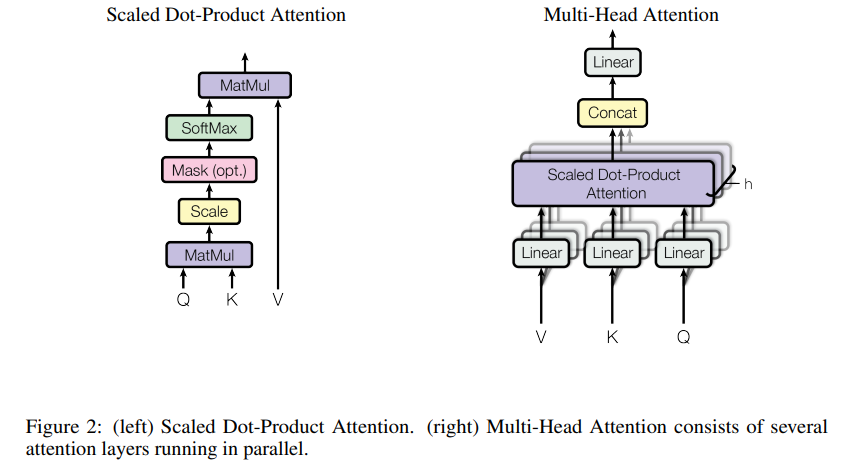
여기서 Attention은 기존의 순환 신경망(RNN) 구조처럼 단어가 순서대로 입력되는 것이 아닌 전체 문장을 한 번에 행렬 형태로 계산을 하는 방법입니다. 하지만 Text의 경우 단어 위치의 정보가 중요하기 때문에 순서 정보를 반영할 수 있도록 Positional Encoding 방법으로 Encoder와 Decoder 각각에 Input Embedding에 더하여 사용하였고, Decoder에서는 자신이 예측해야 할 다음 단어를 참고하지 못하도록 Masking하는 기법을 사용했습니다.
추가적으로 깊고 넓은 신경망의 경우 정보의 손실 가능성이 높기 때문에 Residual connection 방법을 활용하고 과적합을 방지하기 위해 정규화 방법으로 Layer Normalization을 활용하였는데 이름 그대로 Layer별로 Normalize하는 방법입니다.
마지막 층으로는 Linear(=Feed Forward Network)와 Softmax를 사용하여 Classification문제를 푸는 방법으로 학습하도록 구성하였고, Loss의 경우 Cross-Entropy 를 사용했습니다.
- Positional Encoding 방법 참고: https://hi-in.facebook.com/groups/TensorFlowKR/
- Transformer 자세한 설명 참고: https://wikidocs.net/31379
- Vision Transformer 맛보기: 초 간단 논문리뷰 | Vision Transformer(ViT), Google