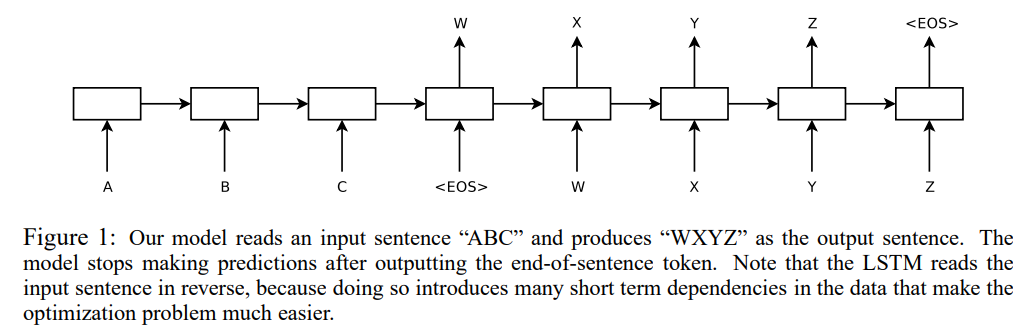
우선 Sequence to Sequence(Seq2Seq) 모델은 RNN의 many-to-many 와 유사한 구조로 시퀀스 형태의 입력값을 넣으면 시퀀스 형태의 출력값을 내놓는 구조입니다. 따라서 번역, 요약, 챗봇 등 다양한 분야에서 활용될 수 있습니다.
RNN(LSTM) 모델을 기반으로 Encoder와 Decoder 부분이 나눠져 있습니다. Encoder에서는 입력값의 context vector(=hidden status)를 생성하고 Decoder에서는 해당 vector를 활용해 재귀적으로 출력값을 만들어내는 구조입니다.
그리고 Encoder와 Decoder는 길이가 고정되어있지만, 각각 다른 최대 길이를 가질 수 있고, 데이터의 길이가 적으면 Padding으로 채웁니다.
Seq2Seq: Encoder-Decoder
RNN의 many-to-many 와 유사한 구조라고 이야기했는데, Decoder에서 다른 부분이 존재합니다.
우선 Seq2Seq 구조의 경우 <EOS> 혹은 <START>, <END> 라는 토큰을 활용하여 시작과 끝맺음을 할 수 있도록 데이터를 구성하여 훈련할 수 있습니다. (참고: 최대 길이보다 길이가 짧은 경우 <END> 토큰 이후에 Padding으로 채우는 방식)
또한 "재귀적"으로 훈련된다는 점도 다릅니다. Decoder의 현재 cell(층)의 input은 이전 cell의 output을 활용하는 것으로 구성되어 있습니다. (RNN은 context vector 하나만 사용)
여기서 만약 Decoder가 시작부터 틀린다면 학습이 잘 되지 않을 수 있습니다. 따라서 Decoder의 현재 cell의 input 값을 실제(정답) 데이터로 사용하는 Teacher Forcing이라는 새로운 학습 방법이 제안됩니다.
# Bad
my_list = [1,2,3,4,5]
my_dict = {'key1':'value1','key2':'value2'}
x = 'Euni'
# Good
my_list = [1, 2, 3, 4, 5]
my_dict = {'key1': 'value1', 'key2': 'value2'}
my_name = 'Euni'
딕셔너리 사용시에 .keys와 .values를 적절하게 사용하지 않음
# Bad - euni: ..? 왜 bad인지 모르겠...다...
for key in my_dict.keys():
print(key)
# Good
for key in my_dict:
print(key)
# Bad
for key in my_dict:
print(my_dict[key])
# Good
for key, value in my_dict.items():
print(value)
컴프리헨션(comprehension)을 사용하지 않음 (혹은 언제나 사용)
컴프리헨션: list, dict 등을 생성하는 경우 for 루프 대신 더 짧은 코드로 해결할 수 있게 도와줌
range(len()) 사용
→ enumerate로 대신 사용할 수 있음
+ 연산자를 사용한 문자열 연결
→ f-string로 대신 사용할 수 있음
mutable value를 디폴트 매개변수로 사용할 때
# Bad
def my_function(i, my_list=[]):
my_list.append(i)
return my_list
# Good
def my_function(i, my_list=None):
if my_list is None:
my_list =[]
my_list.append(i)
return my_list
# >> handler.py
from torchvision import transforms
from ts.torch_handler.image_classifier import ImageClassifier
from torch.profiler import ProfilerActivity
class BinaryClassifier(ImageClassifier):
"""
MNISTDigitClassifier handler class. This handler extends class ImageClassifier from image_classifier.py, a
default handler. This handler takes an image and returns the number in that image.
Here method postprocess() has been overridden while others are reused from parent class.
"""
# euni: preprocessing
image_processing = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
])
def __init__(self):
super(BinaryClassifier, self).__init__()
self.profiler_args = {
"activities" : [ProfilerActivity.CPU],
"record_shapes": True,
}
def postprocess(self, data):
"""The post process of MNIST converts the predicted output response to a label.
Args:
data (list): The predicted output from the Inference with probabilities is passed
to the post-process function
Returns:
list : A list of dictionaries with predictions and explanations is returned
"""
return data.argmax(1).tolist()



](https://user-images.githubusercontent.com/880376/83180095-c44cc600-a0d7-11ea-97c1-23abb4cdbe4d.jpg)