- paper
https://arxiv.org/pdf/2202.03555.pdf - code
https://github.com/pytorch/fairseq/tree/main/examples/data2vec
(Vision: Coming soon!) - reference
Abstract
핵심 idea: Transformer 아키텍처를 사용하는 self-distillation 모델로 입력의 마스킹된 부분을 기반으로 이미지, 자연어, 스피치 전체(multimodal)의 input data의 latent representations를 예측하는 것이다.
- Knowledge distillation이란: 큰 모델에서 작은 모델을 학습하는 것 (Hinton et al., 2015)
1. Introduction
학습 알고리즘은 통합적이지만 여전히 representation은 각 modality의 양식에 대해 개별적으로 학습한다.

- teacher model: original data를 입력하여 representation을 생성
- student model: masked data를 입력하여 original input의 representation을 예측
→ self-distillation
2. Related Work
Self-supervised Learning 이란 | CV, NLP, Speech
Self-supervised Learning 이란 | CV, NLP, Speech
왜 Self-supervised learning을 할까? Issue: 일반적으로 labeled data는 비싸고 대용량 데이터를 구하기 어렵다. Solution Downstream task: 대용량 데이터로 pre-training을 하고 풀고자하는 task에 맞는 데이터..
everyday-deeplearning.tistory.com
Multimodal pre-training
Goal: Modality가 다르더라도 동일한 self-supervised learning을 할 수 있는 방법론을 제안 ⇒ predict : contextualized representations
- modality specific: data2vec에서는 feature 추출하는 부분까지만 각각 task별로 다르게 생성
3. Method & 4. Experimental setup
훈련 샘플의 모든 정보를 인코딩하고 student 모델은 부분적인 보기가 주어지면 이러한 표현을 예측한다.
Model Architecture

표준 Transformer 아키텍처를 사용한다.
Masking

token 단위의 일부를 masking하고 sequence를 transformer 네트워크에 공급한다.
Computer Vision
BEiT masking 방법을 따른다.
image patches를 임의로 masking하는 방법을 사용하는데 인접한 블록을 masking하는 blockwise방법을 사용한다.
Speech processing
wave2vec masking 방법을 따른다.
latent speech representation을 추출하기 위해 cnn 구조를 사용하고 n개의 token을 연속적으로 masking한다.
Natural language processing
RoBERTa masking 방법을 따른다.
BERT에서는 한번만 random masking을 하고 모든 epoch에서 동일한 mask를 반복하지만 RoBERTa에서는 매 epoch마다 다른 masking을 수행하는 dynamic masking 방법을 사용한다. 또한 BERT와 달리 다음 문장을 예측하는 방법은 사용하지 않는다.
Training targets
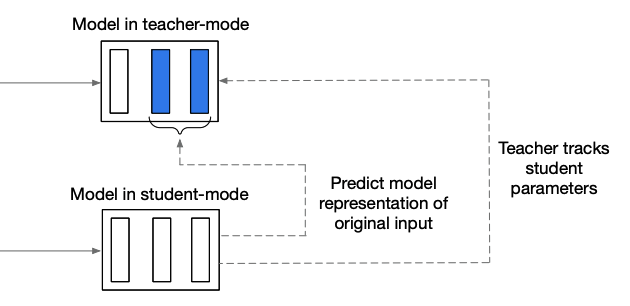
masking된 time-steps부분의 representations만 예측한다.
Teacher parameterization
- EMA(Exponentially Moving Average)
$\triangle \leftarrow \tau\triangle + (1-\tau)\theta$- $\triangle$ : teacher model weight, $\theta$ : student model weight, $\tau$ : target value
→ 학생만 선생님을 통해서 배우는 것이 아니라 선생님도 학생을 통해서 배움(smoothing) - $\tau$: 1인경우 teacher model weight만 사용, 0인경우 student weight만 사용
- $\triangle$ : teacher model weight, $\theta$ : student model weight, $\tau$ : target value
- BYOL
: EMA를 제시한 논문https://arxiv.org/pdf/2006.07733.pdf- oneline networks를 target networks의 representation을 예측하도록 학습함
- target networks의 weights는 online networks의 weight와 EMA로 업데이트 시킴

Targets
normalizing targets
$y_t = \frac{1}{K}\Sigma_{l=L-k+1}^L \hat{a}_t^l$
- K: top k layer
- k test 결과 in Result ) Layer-averaged targets.
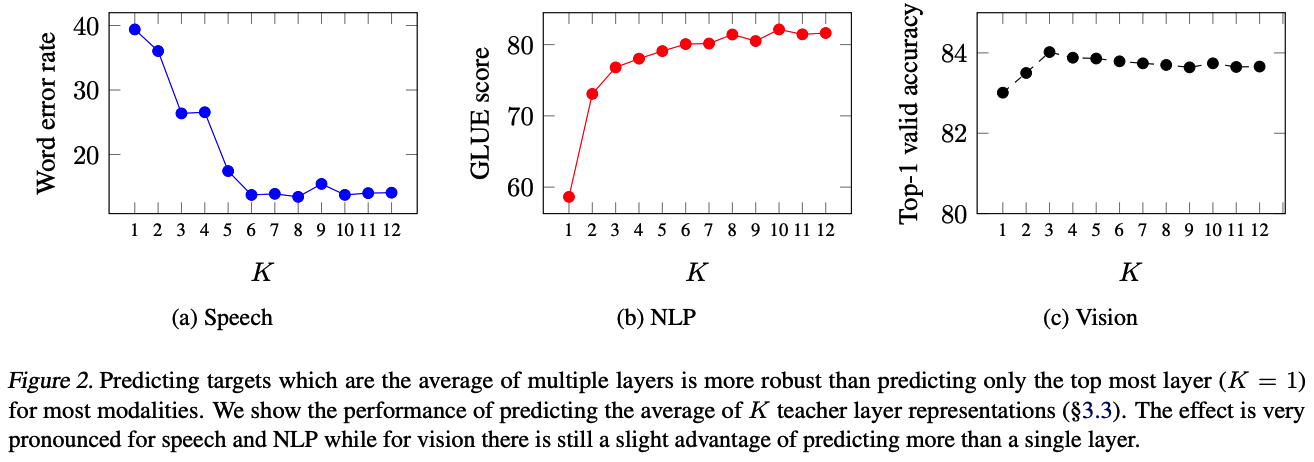
: 여러 계층을 기반으로 하는 대상이 모든 modalities에 대해 최상위 계층(k=1)만 사용하는 것보다 향상되었다.
- k test 결과 in Result ) Layer-averaged targets.
Objective
Smooth L1 loss
$L(y+t, f_t(x)) = \begin{cases} \frac{1}{2}(y_t - f_t(x))^2 / \beta \ \ \ \ \ \ |y_t-f_t(s)| \le \beta \\ (|y_t-f_t(s)| - \frac{1}{2}\beta)\ \ \ \ otherwise\end{cases}$
5. Result
- data2vec Base: L = 12(Transformer blocks), H = 768(hidden dimension)
- data2vec Large: L = 24, H = 1024
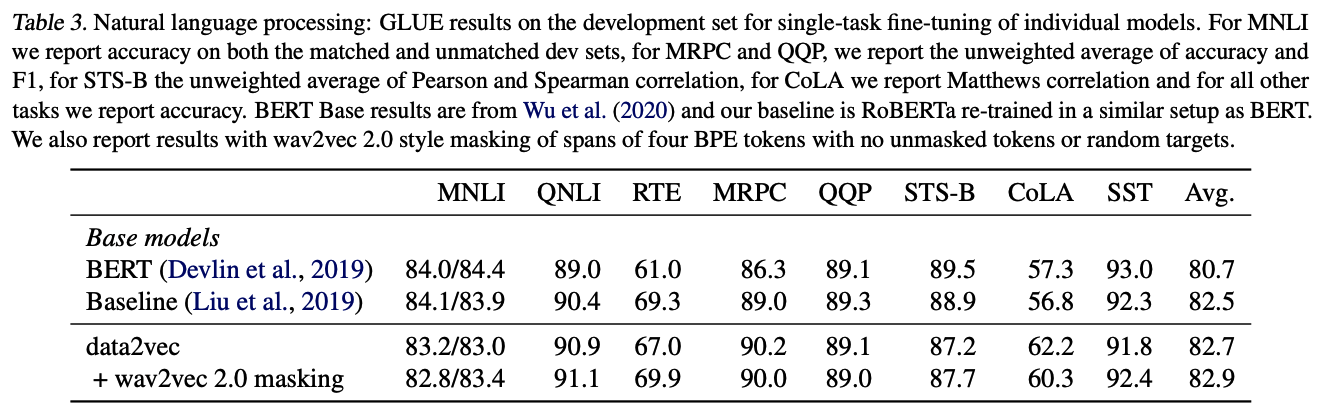
: 모든 modal에서 sota를 준하는 or 뛰어넘는 결과를 얻음
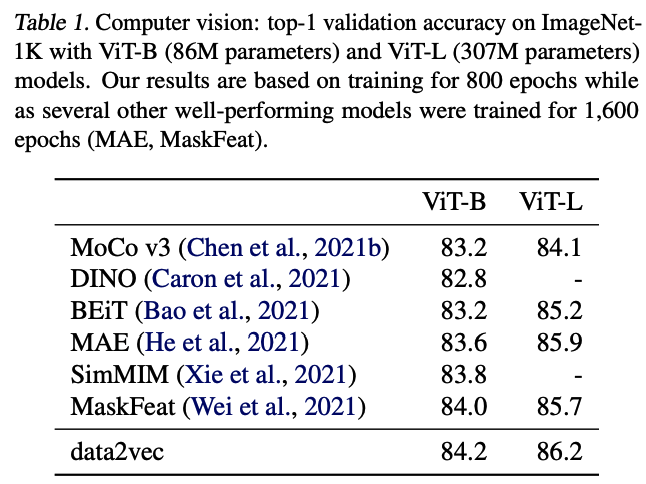
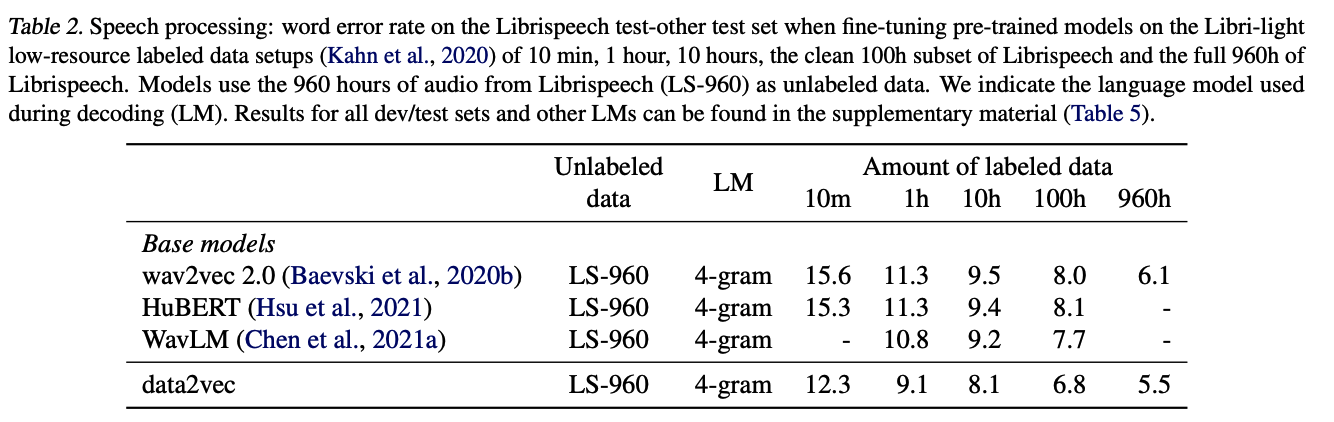
6. Discussion
Structured and contextualized targets.
NLP에서 data2vec은 target units(word/sub-word/character/byte)를 미리 정의하지 않아도 되는 첫 모델이다.
Representation collapse.
- Representation collapse: input에 상관 없이 모두 같은(비슷한) constant vector를 뱉는 현상
- 논문에서 collapse가 발생하는 시나리오를 찾았다.
- the learning rate is too large or the learning rate warmup is too short which can often be solved by tuning the respective hyperparameters.
- τ is too low which leads to student model collapse and is then propagated to the teacher.
- we found collapse to be more likely for modalities where adjacent targets are very correlated and where longer spans need to be masked, e.g., speech.
7. Conclusion
data2vec의 접근 방식은 여전히 modality-specific 인풋 인코더를 사용하고 각 modality별로 masking 방법을 채택했다.
향후 작업에서는 여러 modality를 통합적으로 훈련할 뿐 아니라 modality에 구애받지 않는 단일 마스킹 전략을 조사할 수 있다.
- (Jaegle et al., 2021): 다양한 modality의 raw data에서 작동할 수 있는 Transformer 아키텍처에 대한 task, classification에 대한 supervised learning에 중점을 둠
'초 간단 논문리뷰' 카테고리의 다른 글
| 초 간단 논문리뷰 | Graph-based Semi-supervised Learning (0) | 2022.05.17 |
|---|---|
| 초 간단 논문리뷰 | Graph Neural Networks란 (0) | 2022.04.22 |
| Self-supervised Learning 이란 | CV, NLP, Speech (0) | 2022.03.29 |
| 초 간단 논문리뷰 | Knowledge Distillation: A Survey (0) | 2021.08.27 |
| 초 간단 논문리뷰 | Vision Transformer(ViT), Google (0) | 2021.06.15 |