[논문]
A Style-Based Generator Architectur for Generative Adversarial Networks
[코드]
** 아래의 내용은 위의 논문에서 사용되는 사진과 제가 재해석한 내용입니다.
** 첨언 및 조언 환영합니다!
Abstract
new architecture는 generated(생성된) images에서 높은 수준의 attributes와 stochastic variation을 자동으로 학습하고, 이는 synthesis에 대한 직관적이고 scale-specific control을 가능하게 한다.
The new architecture leads to an automatically learned, unsupervised separation of high-level attributes and stochastic variation in the generated images, and it enables intuitive, scale-specific control of the synthesis.
interpolation 품질과 disentanglement를 정량화하기위해 모든 generator architecture에 적용할 수 있는 두 가지 새로운 자동화 방법을 제안한다.
To quantify interpolation quality and disentanglement, we propose two new, automated methods that are applicable to any generator architecture.
-
interpolation
: In the mathematical field of numerical analysis, interpolation is a type of estimation, a method of constructing new data points within the range of a discrete set of known data points.
-
Disentanglement
: as typically employed in literature, refers to independence among features in a representation.
1. Introduction
generators는 계속해서 black boxes로 작동하고 있으며 최근 노력에도 불구하고 image synthesis process의 다양한 측면에서의 이해가 여전히 부족하다.
Yet the generators continue to operate as black boxes, and despite recent efforts, the understanding of various aspects of the image synthesis process, e.g., the origin of stochastic features, is still lacking.
Our generator는 학습된 constant input에서 시작하여 latent code 기반으로 각 convolution layer에서 이미지의 "style"을 조정하므로 다양한 scales에서 이미지 feature의 strength를 직접적 제어한다.
Our generator starts from a learned constant input and adjusts the “style” of the image at each convolution layer based on the latent code, therefore directly controlling the strength of image features at different scales.
우리는 discriminator나 loss function을 수정하지 않는다.
We do not modify the discriminator or the loss function in any way, and our work is thus orthogonal to the ongoing discussion about GAN loss functions, regularization, and hyper-parameters.
두 가지 새로운 자동화 metrics(perceptural path length와 linear separability)를 제안한다.
As previous methods for estimating the degree of latent space disentanglement are not directly applicable in our case, we propose two new automated metrics —perceptual path length and linear separability — for quantifying these aspects of the generator. Using these metrics, our generator admits a more linear, less entangled representation of different factors of variation.
Finally, we present a new dataset of human faces (Flickr-Faces-HQ, FFHQ).
2. Style-based generator
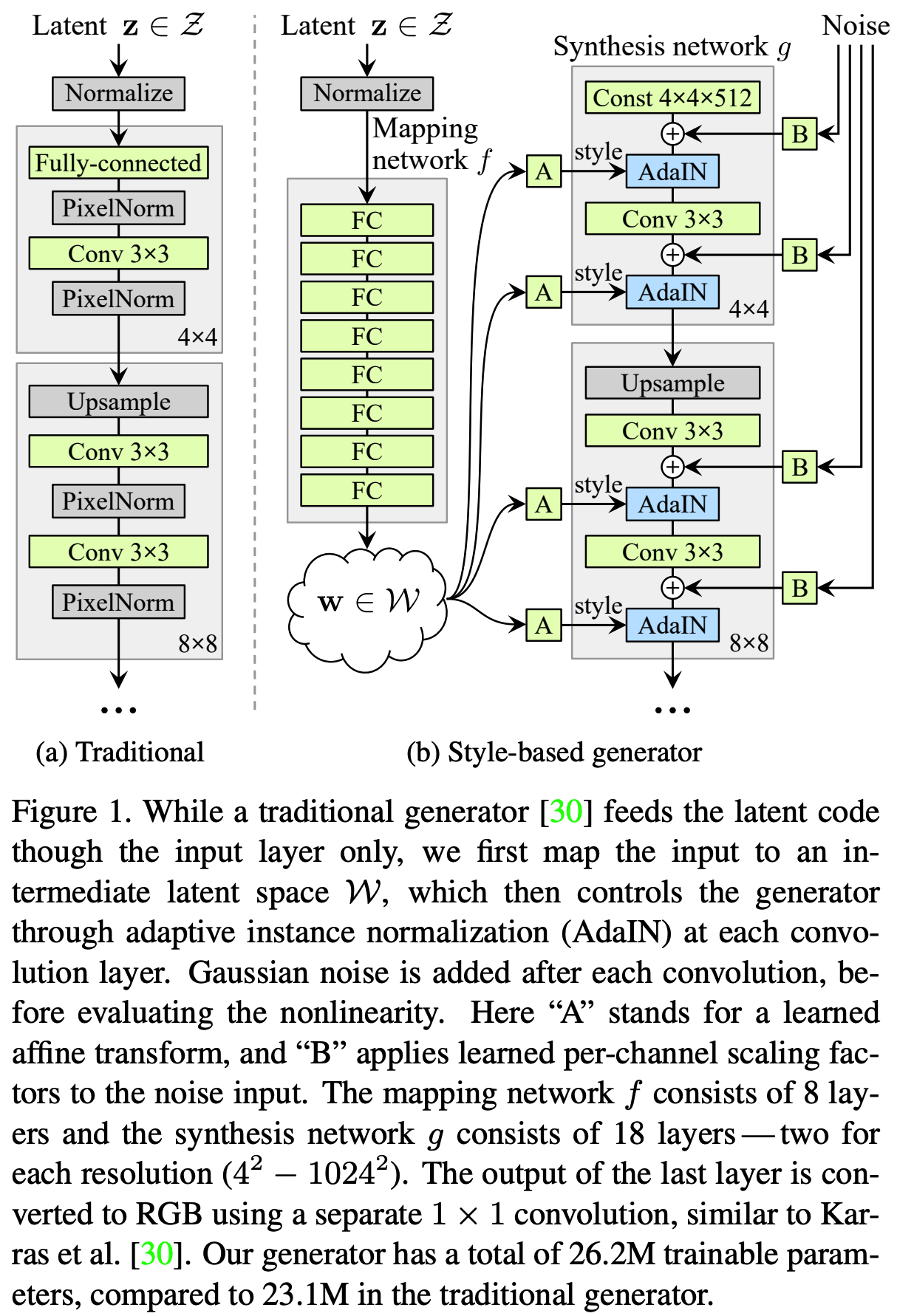
Given a latent code z in the input latent space Z, a non-linear mapping network f : Z → W first produces w ∈ W (Figure 1b, left).
- y = (Figure 1b A)
For simplicity, we set the dimensionality of both spaces to 512, and the mapping f is implemented using an 8-layer MLP, a decision we will analyze in Section 4.1. Learned affine transformations then specialize w to styles y = (ys, yb) that control adaptive instance normalization (AdaIN) [27, 17, 21, 16] operations after each convolution layer of the synthesis network g.
-
IN (Instance Normalization)
$IN(x) = \gamma (\frac{x - \mu(x)}{\sigma(x)}) + \beta$
-
AdaIN ( Adaptive Instance Normalization)
$AdaIN(x_i, y) = y_{s,i} \frac{x_i - \mu}{\sigma(s_i)} + y_{b,i}$ (Eq.1)
where each feature map xi is normalized separately, and then scaled and biased using the corresponding scalar components from style y. Thus the dimensionality of y is twice the number of feature maps on that layer.
AdaIN은 효율성과 간결한 representation으로 우리의 목적에 특히 적합하다.
AdaIN is particularly well suited for our purposes due to its efficiency and compact representation.
explicit(명시적?) noise inputs을 도입하여 stochastic detail을 생성할 수 있는 직접적인 방법을 generator에 제공한다.
Finally, we provide our generator with a direct means to genertate stochastic detail by introducing explicit noise inputs.
2.1. Quality of generated images

마지막으로 결과를 더욱 향상시키는 noise inputs과 neighboring styles을 decorrelates(역상관?/비상관?)하고 생성된 이미지를 보다 fine-grained colntrol 할 수 있는 mixing regularizations를 소개한다.
Finally, we introduce the noise inputs (E) that improve the results further, as well as novel mixing regularization (F) that decorrelates neighboring styles and enable more fine-grained control over the generated imagery (Section 3.1)
-
Section 3.1 참고, mixing reluarization은 network가 인접한 style이 correlated 관계가 있다고 가정하는 것을 방지하는 기술이다.
3.1. Style mixing | This regularization(mixing regularization) technique prevents the network from assuming that adjacent styles are correlated.
2.2. Prior art
[details 논문 참조]
3. Properties of the style-based generator
genertor architecture를 사용하면 scale-specific 수정을 통해 이미지 합성(synthesis)을 컨트롤할 수 있다.
Our generator architecture makes it possible to control the image synthesis via scale-specific modifications to the styles.
각 style은 next AdaIN operation에 overridden(재정의)되기 전에 하나의 convolution만 제어한다.
Thus each style controls only one convolution before being overridden by the next AdaIN operation.
[details 논문 참조]
4. Disentanglement studies
[논문 참조]
5. Conclusion
high-level attribute와 stochastic effects의 분리와 intermediate latent space에 대한 연구가 GAN synthesis의 이해와 controllability의 개선에 유익한 것으로 입증되었다고 믿는다.
This is true in terms of established quality metrics, and we further believe that our investigations to the separation of high-level attributes and stochastic effects, as well as the linearity of the intermediate latent space will prove fruitful in improving the understanding and controllability of GAN synthesis.
나의 결론
- 장점: controllable generator 아이디어 연구 및 입증, FFHQ dataset 제공
- 단점: generator 부분에 포커싱됨, Discriminator에 대한 논의가 없는 것 아쉬움