** 아래의 내용은 위의 논문에서 사용되는 사진과 제가 재해석한 내용입니다.
** 첨언 및 조언 환영합니다!
Abstract
우리의 접근법은 hand-desinged componets의 필요성을 효율적으로 제거하여 detection pipeline을 유연하게 한다.
Our approach streamlines the detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression procedure or anchor generation that explicitly encode our prior knowledge about the task.
새로운 framework(Detection Tranformer, DETR)의 주요 구성요소는 bipartite matching을 통해 unique한 예측을 강제?하는 set(집합) 기반 global loss와 transformer encoder-decoder architecture이다.
The main ingredients of the new framework, called DEtection TRansformer or DETR, are a set-based global loss that forces unique predictions via bipartite matching, and a transformer encoder-decoder architecture.
학습된 object queries의 fixed small set이 주어지면, DETR은 objects와 glabal image context의 관계에 대해 추론하여 최종 예측 set을 병렬로 출력한다.
Given a fixed small set of learned object queries, DETR reasons about the relations of the objects and the global image context to directly output the final set of predictions in parallel.
1. Introduction
object detection의 목적은 관심있는 각 object의 bounding boxes와 category labels의 set을 예측하는 것이다.
The goal of object detection is to predict a set of bounding boxes and category labels for each object of interest.
우리는 surrogate(대리?,대체?) tasks로 우회하기위한 direct set prediction 접근방법을 목표로 한다.
we propose a direct set prediction approach to bypass the surrogate tasks.
end-to-end philosopht(철학?,연구?)은 machine translation or speech recognition과 같은 complex structured 예측 테스크에서 상당한 발전을 가져왔지만 아직 object detection에서는 아니다.
This end-to-end philosophy has led to significant advances in complex structured prediction tasks such as machine translation or speech recognition, but not yet in object detection: previous attempts [43,16,4,39] either add other forms of prior knowledge, or have not proven to be competitive with strong baselines on challenging benchmarks.

DETER은 모든 objects를 한번에 예측하고 예측된 object와 실제 object간의 bipartite matching을 수행하는 set loss function으로 end-to-end 훈련한다.
Our DEtection TRansformer (DETR, see Figure 1) predicts all objects at once, and is trained end-to-end with a set loss function which performs bipartite matching between predicted and ground-truth objects.
기존 detection 방법과 달리 DETR은 customized layer가 필요하지 않으므로 standard CNN과 transformer classes가 포함된 framework에서 쉽게 재현할 수 있다.
Unlike most existing detection methods, DETR doesn’t require any customized layers, and thus can be reproduced easily in any framework that contains standard CNN and transformer classes.1.
matching loss function은 예측을 gound truth object에 고유하게 할당하고 예측된 objects의 permutation(순열?, 가능한 변수 중 하나)이 변하지 않기 때문에 병렬로 내보낼 수 있다.
Our matching loss function uniquely assigns a prediction to a ground truth object, and is invariant to a permutation of predicted objects, so we can emit them in parallel.
보다 정확하게 DETR은 큰 objects에서 훨씬 더 나은 성능을 보여주며, 결과는 transformer의 on-local computations(로컬 컴퓨터로 계산?)에 의해 가능하다. (의역)
More precisely, DETR demonstrates ignificantly better performance on large objects, a result likely enabled by the on-local computations of the transformer.
하지만, small objects에 관하여 더 낮은 성능을 갖는다.
It obtains, however, lower performances on small objects.
실험에서, 사전 훈련된 DETR 위의 simple segmentation head가 Panoptic Segmentation의 competitive baselines을 능가한다는 것을 보여준다. (4.2확인)
In our experiments, we show that a simple segmentation head trained on top of a pretrained DETR outperfoms competitive baselines on Panoptic Segmentation [19], a challenging pixel-level recognition task that has recently gained popularity.
2. Related work
(논문 참고)
3. The DETR model

detection에서 direct set precditions를 위해서는 2가지 필수적인 요소가 있다.
(1) 예측된 box와 실제 box 사이에 고유한 matching을 강제하는 set prediction loss.
(2) object set를 예측하고 그 관계를 모델링하는 architecture.
Two ingredients are essential for direct set predictions in detection:
(1) a set prediction loss that forces unique matching between predicted and ground truth boxes;
(2) an architecture that predicts (in a single pass) a set of objects and models their relation. We describe our architecture in detail in Figure 2.
3.1 Object detection set prediction loss
(이해 잘 안됨, 다시 리뷰하기)
Each element i of the ground truth set can be seen as a yi = (ci , bi) where ci is the target class label (which may be ∅) and bi ∈ [0, 1]^4 is a vector that defines ground truth box center coordinates and its height and width relative to the image size.
Bounding box loss.
The second part of the matching cost and the Hungarian loss is Lbox(·) that scores the bounding boxes. Unlike many detectors that do box predictions as a ∆ w.r.t. some initial guesses, we make box predictions directly.
3.2 DETR architecture
전반적인 DETR architecture는 놀라울 정도로 간단하고 Figure 2에 묘사되어있다.
The overall DETR architecture is surprisingly simple and depicted in Figure 2.
3가지 주요 구성요소가 있다.
- compact한 feature representation을 추출하기 위한 CNN backbone
- encoder-decoder transformer
- 최종 detection 예측을 만드는 간단한 FFN
It contains three main components, which we describe below: a CNN backbone to extract a compact feature representation, an encoder-decoder transformer, and a simple feed forward network (FFN) that makes the final detection prediction.
Inference code for DETR can be implemented in less than 50 lines in PyTorch [32]. (A.6 PyTorch inference cod)
import torch
from torch import nn
from torchvision.models import resnet50
class DETR(nn.Module):
def __init__(self, num_classes, hidden_dim, nheads,
num_encoder_layers, num_decoder_layers):
super().__init__()
# We take only convolutional layers from ResNet-50 model
self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2])
self.conv = nn.Conv2d(2048, hidden_dim, 1)
self.transformer = nn.Transformer(hidden_dim, nheads,
num_encoder_layers, num_decoder_layers)
self.linear_class = nn.Linear(hidden_dim, num_classes + 1)
self.linear_bbox = nn.Linear(hidden_dim, 4)
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
x = self.backbone(inputs)
h = self.conv(x)
H, W = h.shape[-2:]
# print(self.col_embed[:W].unsqueeze(0).shape, self.row_embed[:H].unsqueeze(1).shape) # torch.Size([1, 38, 128]) torch.Size([25, 1, 128])
pos = torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1)
h = self.transformer(pos + h.flatten(2).permute(2, 0, 1),
self.query_pos.unsqueeze(1))
return self.linear_class(h), self.linear_bbox(h).sigmoid()
detr = DETR(num_classes=91, hidden_dim=256, nheads=8, num_encoder_layers=6, num_decoder_layers=6)
detr.eval()
inputs = torch.randn(1, 3, 800, 1200)
logits, bboxes = detr(inputs)
Backbone.

Typical values we use are C = 2048 and H, W = $\frac{H_0}{32}, \frac{W_0}{32}$.
Transformer encoder.
First, a 1x1 convolution reduces the channel dimension of the high-level activation map f from C to a smaller dimension d. creating a new feature map z0 ∈ R d×H×W .
The encoder expects a sequence as input, hence we collapse the spatial dimensions of z0 into one dimension, resulting in a d×HW feature map.
Each encoder layer has a standard architecture and consists of a multi-head self-attention module and a feed forward network (FFN).
Since the transformer architecture is permutation-invariant, we supplement it with fixed positional encodings [31,3] that are added to the input of each attention layer.
Transformer decoder.
The decoder follows the standard architecture of the transformer, transforming N embeddings of size d using multi-headed self- and encoder-decoder attention mechanisms.
The difference with the original transformer is that our model decodes the N objects in parallel at each decoder layer, while Vaswani et al.
These input embeddings are learnt positional encodings that we refer to as object queries, and similarly to the encoder, we add them to the input of each attention layer.
Prediction feed-forward networks (FFNs).
The final prediction is computed by a 3-layer perceptron with ReLU activation function and hidden dimension d, and a linear projection layer.
The FFN predicts the normalized center coordinates, height and width of the box w.r.t. the input image, and the linear layer predicts the class label using a softmax function.
Since we predict a fixed-size set of N bounding boxes, where N is usually much larger than the actual number of objects of interest in an image, an additional special class label ∅ is used to represent that no object is detected within a slot. (“background” class와 비슷한 역할을 함)
Auxiliary decoding losses.
We add prediction FFNs and Hungarian loss after each decoder layer. All predictions FFNs share their parameters.
4. Experiments
자세한 사항 (논문참고)
| Technical details | values |
| optimizer | AdamW |
| transformers' learning rate | $10^{-4}$ |
| backborne's lr | $10^{-5}$ |
| weight decay | $10^{-4}$ |
| backbones | ResNet50, ResNet-101 |
4.4 DETR for panoptic segmentation
Panoptic segmentation [19] has recently attracted a lot of attention from the computer vision community. Similarly to the extension of Faster R-CNN [37] to Mask R-CNN [14], DETR can be naturally extended by adding a mask head on top of the decoder outputs.
Predicting boxes is required for the training to be possible, since the Hungarian matching is computed using distances between boxes.
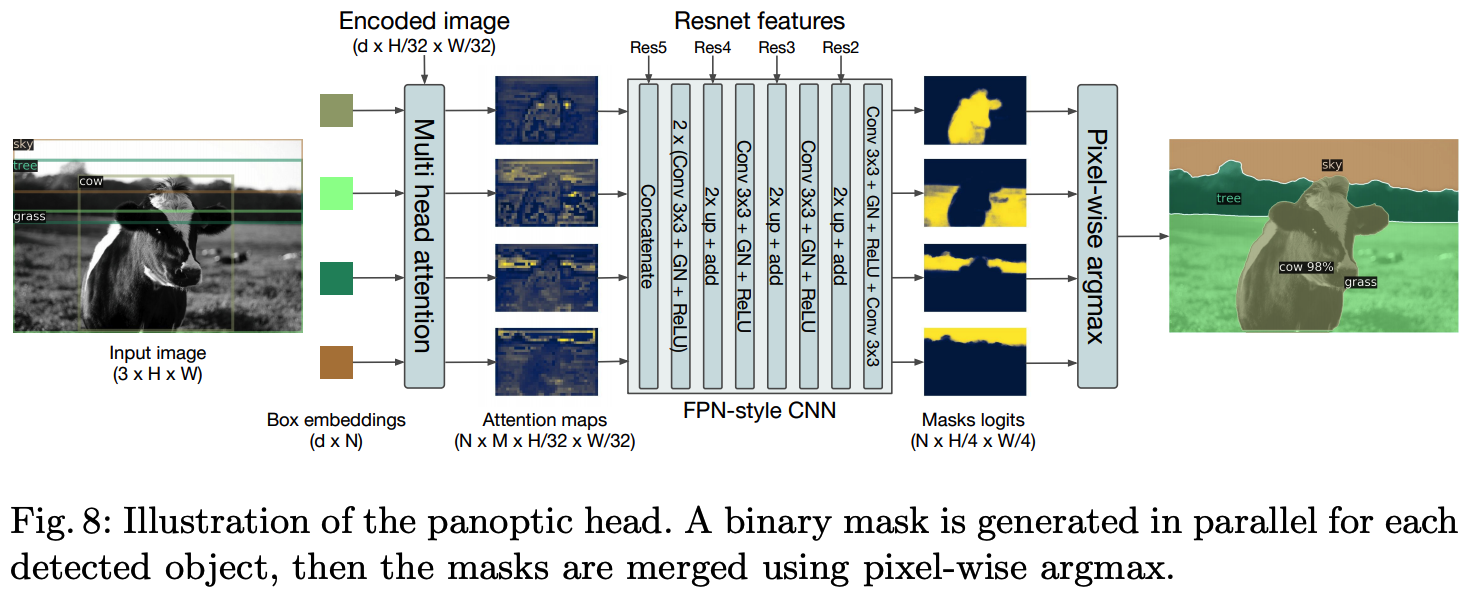
We also add a mask head which predicts a binary mask for each of the predicted boxes, see Figure 8.
It takes as input the output of transformer decoder for each object and computes multi-head (with M heads) attention scores of this embedding over the output of the encoder, generating M attention heatmaps per object in a small resolution.
5. Conclusion
direct set prediction을 위한 transformers와 bipartite matching loss를 기반으로 object detection system을 위한 새로운 구조인 DETR을 소개했다.
We presented DETR, a new design for object detection systems based on transformers and bipartite matching loss for direct set prediction.
self-attention을 이용한 global information processing 덕분에 Faster R-CNN보다 large objects에 대해 훨씬 더 나은 성능을 달성한다.
In addition, it achieves significantly better performance on large objects than Faster R-CNN, likely thanks to the processing of global information performed by the self-attention.
나의 결론
장점 :
- Transformer를 Vision task에서 적용함
- 기존에 사용하던 ResNet과 Transformer를 이용하여 간단한 basic 코드로 large object의 detection 성능을 높임
- pre-trained DETR 위에 간단한 Multi-head attention을 활용하여 segmentation task에 사용할 수 있음
단점(아쉬운 점) :
small object, 겹치는 object의 detection 성능 향상이 필요할 것으로 보임