** 아래의 내용과 이미지는 위의 논문을 기반으로 작성하였습니다.
** 수정할 부분이나 의견이 있다면 댓글로 달아주세요~
[참고] 미리보기
GAN Inversion : GAN을 거꾸로 하는 것

: real image를 latent space의 적절한 latent code로 Inversion하는 task
→ latent space를 배운다. (explainable)
⇒ latent space 상의 각각의 latent code로 부터 realistic한 image를 얻을 수 있다.
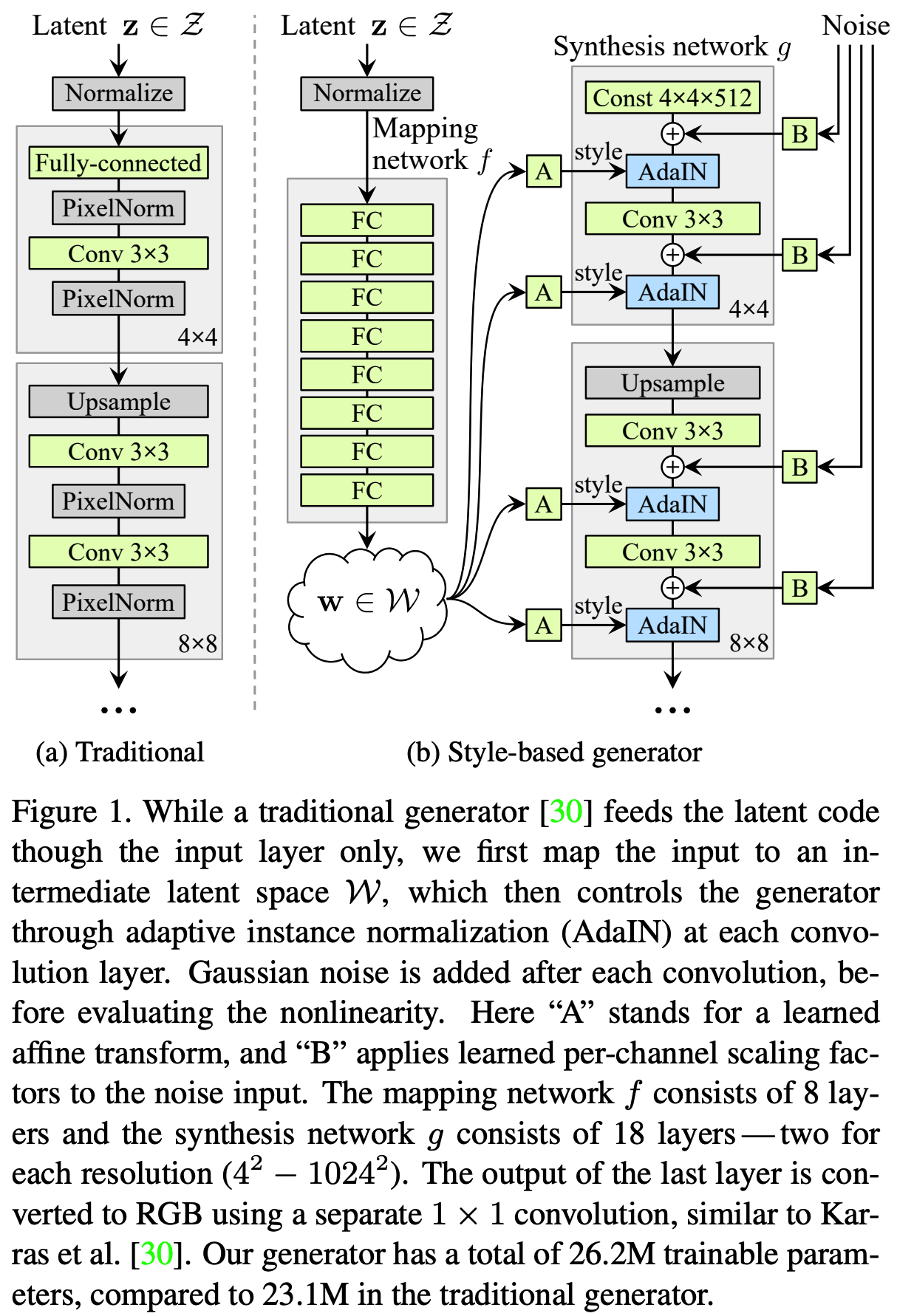
StyleGAN: 각 layer 마다 hierarchical latent code를 부여하여 generation

: 위의 구조는 realistic한 output을 얻을 수 있을뿐만 아니라 각 layer별로 latent vector의 의미가 다르게 훈련됨 → output 이미지를 조절할 수 있다.
Abstract
기존 GAN의 경우 real image를 editing하기위한 semantics를 배우기 어려웠다.
현존하는 inversion methods는 pixel 기준으로 target image를 reconstucting(재구성)하기 때문에 original latent space에 semantic한 inverted code를 배치시키는데 실패했다.
논문에서는 이러한 문제를 해결하기 위해 in-domain GAN inversion방식을 제안한다. input image를 reconstuct할 뿐아니라 image editing을 위한 semantically meaningful latent code로 invert할 수 있다.
→ in domain ( latent space 안에서) GAN inversion을 제시, real image에 semantic한 editing할 수 있다.
1 Introduction

- in domain 예: like face, tower, bedroom
- semantic 예 : eyeglasses, smile (→ face에서 자연스럽게?)
GAN은 image를 생성하는 generator와 실제 이미지와 가짜 이미지를 판별하는 discriminator로 구성되어있다.
최근 연구에서 GAN이 latnet space에서 풍부한 semantics를 encoding하는 방법으로 학습하고 latent code를 변경하면 output image에서 해당하는 attributes를 조작(manipulation)할 수 있다는 것을 보여줬다.
하지만, real image를 입력으로 사용하여 latent code를 추론하는 기능이 없기 때문에 이러한 manipulation을 적용하기에는 여전히 어렵다.
GAN Inversion으로 image sapce를 latent space로 mapping하여 generation process로 되돌리려는 시도가 많이 있지만, 기존 방법은 주로 input image의 pixel을 기준으로 reconstruct하는 것에 중점을 두었다.
하지만 이 논문에서는 GAN Inversion 작업에서 pixel 수준 뿐 아니라 latent space에 encoding된 semantic knoledge와 align되어야한다고 주장한다. 이런 semantically meaningful codes는 GAN이 학습한 domain에 종속되기 때문에 in-domian code라고 부른다.
2 In-Domain GAN Inversion

GAN Invert할 때 input image의 pixel값을 복구하는 것 외에도 inverted code가 semantically 의미있는지 여부도 고려한다.
여기서 semantics는 GAN이 관찰된 data로부터 학습한 emergent knoledge를 의미한다.
방법: as shown in Fig.2.
- novel domain-guided encoder를 훈련하여 encoder에서 생성된 모든 code가 domain내에 있도록 image space를 latent space에 매핑한다.
- inverted code의 semantic property에 영향을 주지않고 pixel 값을 더 잘 reconstruct하기위해 instance-level domain-regularized optimization한다.
Problem Statement.
GAN model은 generator G(·) : Z → X 와 discriminator D(·) 로 구성되어있다. GAN Inversion은 주어진 실제 이미지 x real을 복구하기 위해 최상의 잠복 코드 z inv를 찾는 reverse mapping of G(·)을 학습한다.
Choice of Latent Space.
일반적으로 GAN은 미리 정의된 distribution space (such as normal distibution) Z에서 latent code z를 샘플링한다.
최근 StyleGAN 모델은 Multi-Layer Perceptron (MLP)를 이용하여 initial latent space Z를 두번째 latent space W에 매핑한다음 w ∈ W를 Generator에 사용하는 (additional mapping) 방법을 제안했다. → GAN inversion task에서 많이 사용됨
3가지 이유로 이 논문에서도 inversion space로 W space를 선택한다.
(i) We focus on the semantic (i.e., in-domain) property of the inverted codes, making W space more appropriate for analysis.
(ii) Inverting to W space achieves better performance than Z space [35].
( but our approach can be performed on the Z space as well. For simplicity, we use z to denote the latent code in the following sections. )
(iii) It is easy to introduce the W space to any GAN model by simply learning an extra MLP ahead of the generator.
2.1 Domain-Guided Encoder
Fig.2(a)의 위에 있는 (conventional encoder)를 보면, latent codes $z^{sam}$는 랜덤하게 샘플링되어 Generator에 들어가고 연관된 synthesis $x^{syn}$ 이미지를 얻는다.
그리고 Encoder는 $x^{syn}$ 를 input으로 $z^{sam}$ supervisions으로 하고 eq1으로 훈련된다.
$min_{\Theta_E}L_E = ||z^{sam} - E(G(z^{sam}))||_2$, (1)
where $||·||_2$ denotes the $l_2$ distance and $\Theta_E$ represents the parameters of the encoder E(·).
→ it is not powerful enough to train an accurate encoder and cannot provide its domain knowledge
이러한 문제를 해결하기위해 저자는 domain-guided encoder(in the bottom row of Fig.2(a))를 제안한다.
→ 기존 gan 방법과 달리 latent space가 아닌 real image space에서 input image를 reconstruct 함 : G(E(xreal))
- The output of the encoder is fed into the generator to reconstruct the input image such that the objective function comes from the image space instead of latent space.
- Instead of being trained with synthesized images, the domain-guided encoder is trained with real images, making our encoder more applicable to real applications.
- To make sure the reconstructed image is realistic enough, we employ the discriminator to compete with the encoder. (both two components of GAN are used).
이 방식으로 GAN 모델에서 최대한 많은 정보를 얻을 수 있다.
The training process can be formulated as LE, LD
$$min_{\Theta_E}L_E = ||x^{real}-G(E(x^{real}))||2 \\ + \lambda{vgg} ||F(x^{real}) - F(G(E(x^{real})))||2 \\ - \lambda{adv} \mathbb{E}{x^{real} \sim P{data}}[D(G(E(x^{real})))],$$ (2)
- loss1: per pixel loss
- $||x^{real}-G(E(x^{real}))||_2$ : x와 (x >> Encoder >> generator >>) z를 비교하는 loss,
- loss2: perceptual loss
- F(·) denotes the VGG feature extraction model.
- perceptual loss: Perceptual loss란 [11]에서 처음으로 제안된 손실 함수로 입력과 GT를 미리 학습해 놓은 다른 딥러 닝 기반의 영상 분류 네트워크에 통과 시킨 후 얻 은 feature map 사이의 손실을 최소화 하는 방향 으로 필터 파라미터를 학습한다.
- source: http://www.kibme.org/resources/journal/20200504094149078.pdf
- $\lambda_{vgg} ||F(x^{real}) - F(G(E(x^{real})))||_2$ : vgg loss 사용
- F(·) denotes the VGG feature extraction model.
- loss3: discriminator loss
- Pdata denotes the distribution of real data
- $\lambda_{adv} \mathbb{E}{x^{real} \sim P{data}}[D(G(E(x^{real})))]$ : discriminator를 training용
$$min_{\Theta_D} L_D = \mathbb{E}{x^{real} \sim P{data}}[D(G(E(x^{real})))] \\ - \mathbb{E}{x^{real} \sim P{data}}[D(x^{real})] \\ + \frac{\gamma}{2} \mathbb{E}{x^{real} \sim P{data}} [|| \nabla_x D(x^{real})||_2^2],$$ (3)
- loss 1: discriminator loss
- $\mathbb{E}{x^{real} \sim P{data}}[D(G(E(x^{real})))] - \mathbb{E}{x^{real} \sim P{data}}[D(x^{real})]$ : 가짜(생성된 이미지), real image discriminator loss
- loss 2: gradient regularization
- $\frac{\gamma}{2} \mathbb{E}{x^{real} \sim P{data}} [|| \nabla_x D(x^{real})||_2^2]$
: 변화량에 penalty - γ is the hyper-parameter
- $\frac{\gamma}{2} \mathbb{E}{x^{real} \sim P{data}} [|| \nabla_x D(x^{real})||_2^2]$
2.2 Domain-Regularized Optimization
distribution level에서 mapping을 학습하는 GAN의 generation process와 달리, GAN inversion은 주어진 개별 image를 가장 잘 reconstruct하는 instance-level task와 비슷하다.
이러한 관점에서 볼때 encoder 만으로는 representation capability이 제한되어 완벽한 reverse mapping을 학습하기 어렵다. 따라서, 여전히 code를 pixel 값에서 개별 target image와 더 잘 fit하게 수정해야한다.
The top row of Fig.2(b)에서 latent code는 generator만을 기반으로 'freely' 최적화된다.
이것은 latent code를 제약이 없기때문에 an out-of-domain inversion이 발생할 가능성이 매우 높다.
The bottom of Fig.2(b)에서 보이는 것처럼, 2가지 개선사항으로 domain-regularized optimization을 설계한다.
- We use the output of the domain-guided encoder as an ideal starting point which avoids the code from getting stuck at a local minimum and also significantly shortens the optimization process.
- We include the domain-guided encoder as a regularizer to preserve the latent code within the semantic domain of the generator.
To summarize, the objective function for optimization is
$$z^{inv} = argmin_z (||x - G(z)||2 \\+ \lambda{vgg}||F(x) - F(G(x))||2 \\+ \lambda{dom}||z-E(G(z))||_2),$$ (4)
- x is the target image to invert
- λvgg : the perceptual loss
- λdom: encoder regularizer respectively
- $\lambda_{dom}||z-E(G(z))||_2$
- z와 (z >> Generator >> Encoder >>) z' 을 같도록 훈련 ⇒ semantic 의미를 잘 갖추도록 (z를 이미 잘 구해놓았다는 전제하고 z를 fine-tuning, 최적화)
3 Experiments
[논문 참고]

4 Discussion and Conclusion

in domain으로 훈련해서 out of distribution에서는 별로다.(in Fig.10) → semantic한 훈련이 되었다는 의미로 볼 수 있다.
결론적으로, in-domain inversion은 pixel level과 semantic level 모두에서 대상 이미지를 복구하는 데 가장 적합한 (latent) code를 찾는 것을 목표로 하며 real image editing을 상당히 용이하게 한다.