AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
- 논문
- code
- 참고
** 아래의 내용과 이미지는 위의 논문을 기반으로 작성하였습니다.
** 수정할 부분이나 의견이 있다면 댓글로 달아주세요~
ABSTRACT
Transfomer architecture는 NLP task에서 공공연히 standard한 모델이 되어왔지만 CV(Computer Vision) task에서는 여전히 한계가 있다.
우리는 CNN을 사용할 필요없이 image를 sequcese of patches로 직접 적용하는 transformer 모델 자체가 classification task에서 좋은 성능을 보인다는 것을 보여준다.
대량의 data를 pre-trained하고 multiple mid-sized or small images를 banchmarks (ImageNet, CIFAR-100, VTAB, etc.)로 transferred할 때 ViT는 적은 computational resource를 사용하여 훈련하여도 SOTA와 비교해도 좋은 결과를 얻을 수 있다.
1 INTORDUCTION
Transformer(Self-attention-based architectures)가 large dataset으로 훈련된 pre-trained모델로 NLP task에서 많이 채택되고 있다.
CV에서는 CNN을 사용하는 경우가 여전히 우세하다. attention aptterns을 사용할 때 여러 test가 있었지만 아직 충분히 scaled dffectively 모델이 없다.
우리는 image를 잘라서 patches(treated the same way as tokens (words))로 만들고 sequence를 linear ebedding로 만들어 transformer에 넣었다. ViT는 충분한 scale로 pre-trained하고 fewer datapoints로 task를 trasnferred할때 상당히 좋은 결과를 달성할 수 있다.
2 RELATED WORK
Naive application of self-attention to images would require that each pixel attends to every other pixel. With quadratic cost in the number of pixels, this does not scale to realistic input sizes. Thus, to apply Transformers in the context of image processing, several approximations have been tried in the past.
Many of these specialized attention architectures demonstrate promising results on computer vision tasks, but require complex engineering to be implemented efficiently on hardware accelerators.
Most related to ours is the model of Cordonnier et al. (2020), which extracts patches of size 2 × 2 from the input image and applies full self-attention on top. This model is very similar to ViT, but our work goes further to demonstrate that large scale pre-training makes vanilla transformers competitive with (or even better than) state-of-the-art CNNs. Moreover, Cordonnier et al. (2020) use a small patch size of 2 × 2 pixels, which makes the model applicable only to small-resolution images, while we handle medium-resolution images as well.
We focus on these two latter(ImageNet-21k and JFT-300M) datasets as well, but train Transformers instead of ResNet-based models used in prior works.
3 METHOD
In model design we follow the original Transformer (Vaswani et al., 2017) as closely as possible. An advantage of this intentionally simple setup is that scalable NLP Transformer architectures – and their efficient implementations – can be used almost out of the box.
3.1 VISION TRANSFORMER (ViT)
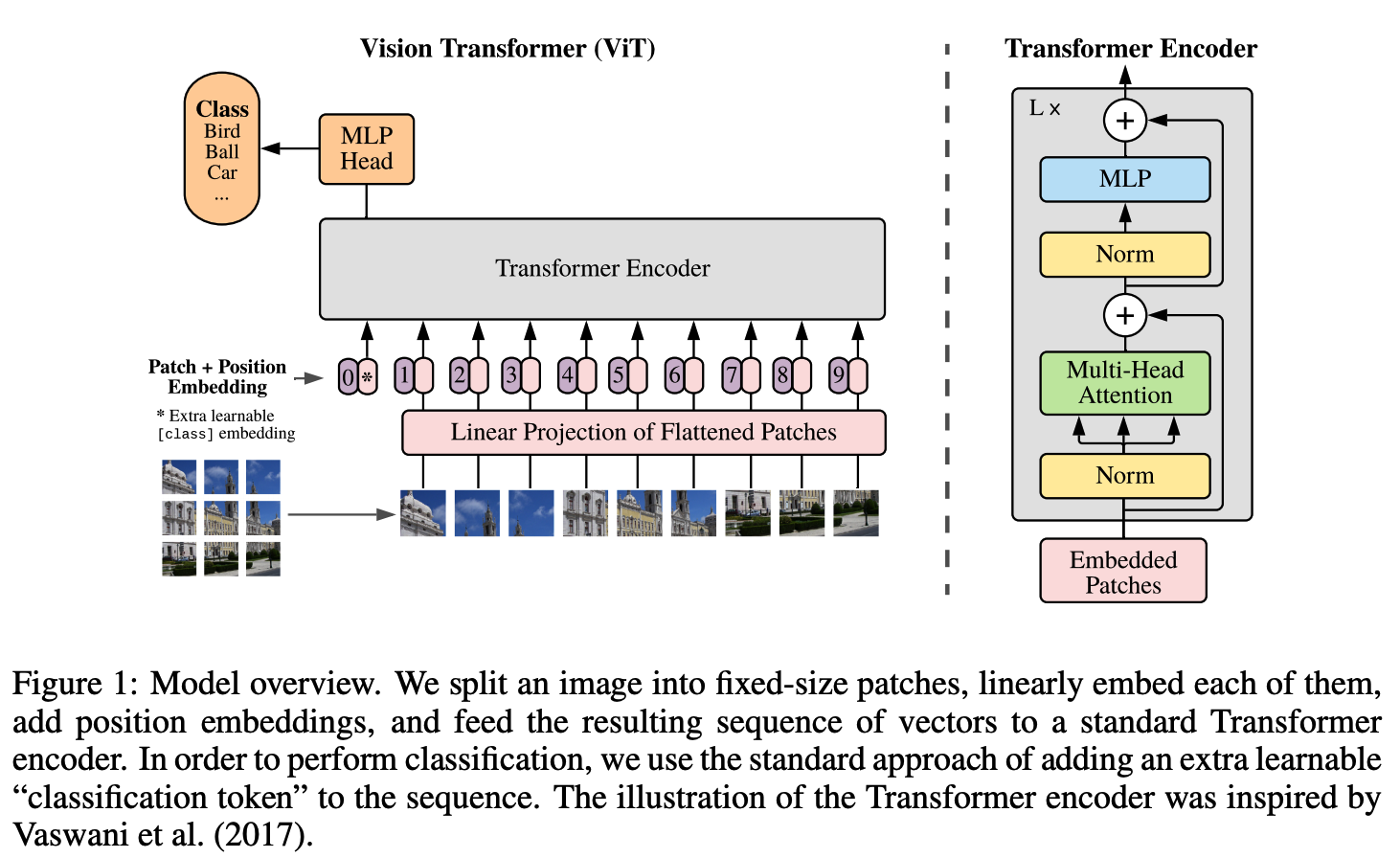
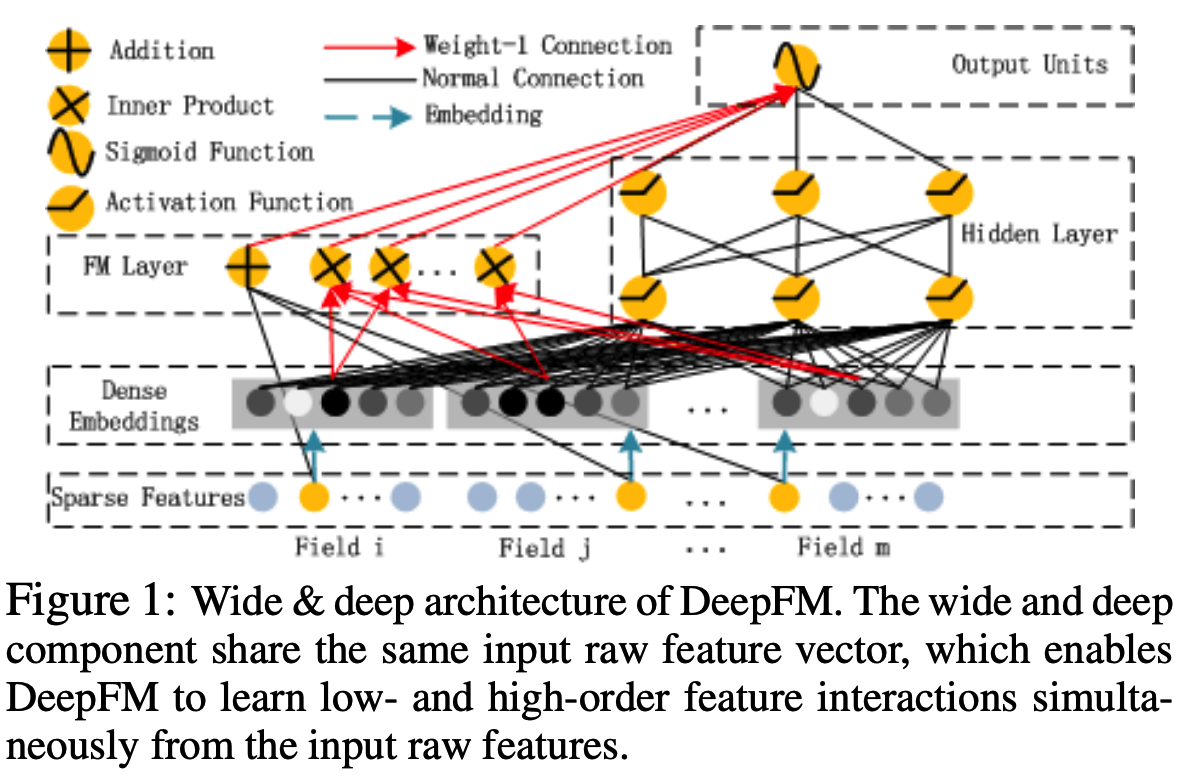
standard Transformer는 input으로 1D sequnce of token embeddings을 가지기 때문에 2D images를 다루기 위해 patches(이미지를 자른 것)를 flatten하고 trainable linear projection을 사용하여 D 차원에 mapping한다.
potision embeddings(1D)는 위치 정보를 유지하기 위해 patch embeddings에 합산한다. sequence of embedding vectors는 encoder의 입력으로 사용된다.
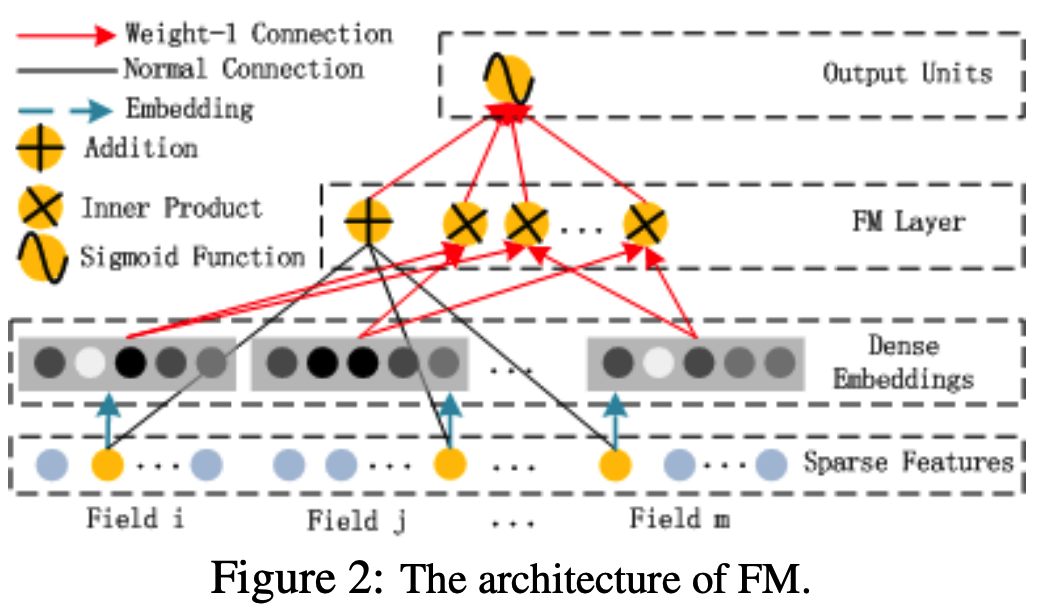
- linear projection (Eq. 1).the patch embedding projection E (Eq. 1) is applied to patches extracted from a CNN feature map.
- $z_0 = [x_{class}; x^1_pE;x^2_pE; ...;x^N_pE] + E_{pos}, E \in \mathbb{R}^{(P^2C) \times D}, E_{pos} \in \mathbb{R}^{(N+1)\times D}$
BERT의 [class] token과 비슷하게, (Transformer encoder $(z^0_L)$ 의 output 상태가 image representation y 역할을 하는) sequnce of embedded patches 앞에 learnable embedding을 추가한다.
- (Eq.4)
- $y = LN(z^0_L)$ , Layernorm (LN)
Transformer Encoder는 Multihead self-attention(MSA) 과 MLP block (Eq. 2, 3)의 layers로 구성된다. Layernorm (LN)은 모든 block 이전에 적용되고 residual connection (+ 기호 사용)은 모든 block 이후에 적용된다.
- (Eq.2)Multihead self-attention(MSA) is an extension of SA in which we run k self-attention operations, called “heads”, in parallel, and project their concatenated outputs. (in Appendix A)
- $z'l = MSA(LN(z{l-1})) + z_{l-1}$ $l = 1 ... L$
- (Eq.3)MLP에는 2개의 GELU layers 사용
- *참고: Gaussian Error Linear Units (GELUs) is an activation function. (non-linear) https://paperswithcode.com/method/gelu
- $z_l = MLP(LN(z'_l)) + z'_l$ $l = 1 ... L$
Inductive bias.
CNN에서는 locality, 2D neighborhood structure, and translation equivariance가 전체 모델을 통해 각 layer로 다시 들어간다.
ViT에서는 MLP layers만 local and translationally equivariant이고, self-attention layers는 global이다.
Hybrid Architecture.
hybrid model에서는 patch embedding projection E(Eq. 1)에 CNN feature map으로 부터 추출된 patches가 적용된다. 특별한 경우로, patches는 spatial size 1x1 가질수 있다. input sequence는 단순히 spatial dimensions of the feature map을 flattening하고 Transformer dimesion을 projecting하여 얻는다. ( Abstract 에서는 CNN 필요없다고 했지만...)
3.2 FINE-TUNING AND HIGHER RESOLUTION
일반적으로 대규모 데이터셋에 대해 ViT를 pre-train하고 (smaller) downstream task로 fine-tune한다. 이를 위해 pre-trained prediction head를 제거하고 zero-initialize된 DxK(K: the number of downstream classes) feedforward layer를 연결한다. 종종 higer resolution으로 fine-tune하는 것이 도움이 된다.
hider resolution을 사용할 때는 patch size를 같게 유지하기 때문에 effective sequence length가 커진다. ViT는 임의의 sequence length를 처리할 수 있지만 pre-trained position embeddings가 더 이상 의미가 없을 수 있다. 따라서 원본에서 location에 따라 pre-trained position embeddings의 2D interpolation을 수행한다. (수동으로 bias 넣음)
4 EXPERIMENTS
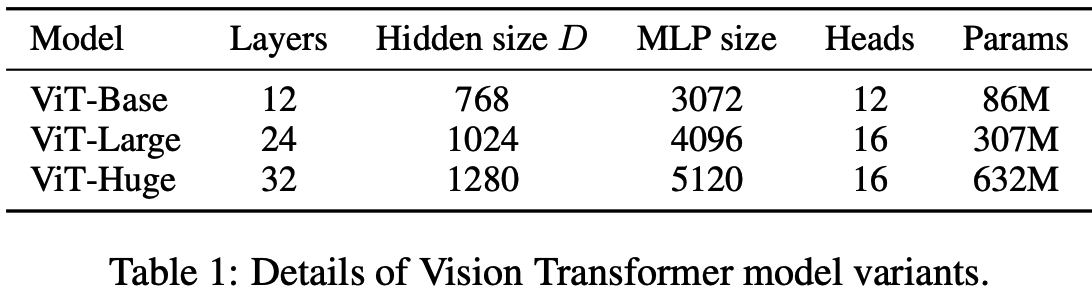

ViT-L/16 means the “Large” variant with 16×16 input patch size.
Note that the Transformer’s sequence length is inversely proportional to the square of the patch size, thus models with smaller patch size are computationally more expensive.

Globally, we find that the model attends to image regions that are semantically relevant for classification (Figure 6).
5 CONCLUSION
image recognition을 Transformers에 직접 적용해보았다. 기존 computer vision에서 self-attention을 사용하는 방법과 달리, 이 논문에서는 image를 a sequence of patches로서 NLP에서 사용되는 standard Transformer encoder로 처리한다.
- Challenges
- 다른 CV task(detection and segmentation)에 ViT 적용하기
- self-supervised pre-training 방법 탐색하기
나의 결론
- 최근 동향을 보면, Transformer는 CNN, LSTM 과 같은 general deep learning model이 되었다. 오히려 NLP, CV 등 task에 국한되지 않고 대체적으로 (SOTA에 준하는 혹은 뛰어넘는) 좋은 성능을 보이고 있다. (nlp와 달리 image는 local&global(position) feature(information)가 중요함)
- 이 논문에서는 image input을 transformer model에 어떻게 넣어야 효과적일까? 에 대한 방법을 소개한다.
- 방법요약: patch로 이미지를 잘라서(or CNN으로 feature map 생성해서-hybrid architecture) 1dim으로 flatten 시키고 (Transformer가 1d를 input으로 받음) 각 patch별로 position embedding을 붙여서 transformer에 넣는다. (idea는 단순함)
- 아래 이미지 Source: https://www.youtube.com/watch?v=QkwNdgXcfkg


- 다만, 데이터셋이 적으면 train 하기 어려움 → (google에서 ViT를 large dataset으로 pre-train함) fine-tuning(transferred learning)해서 사용하면 좋은 성능 기대할 수 있음
- 방법요약: patch로 이미지를 잘라서(or CNN으로 feature map 생성해서-hybrid architecture) 1dim으로 flatten 시키고 (Transformer가 1d를 input으로 받음) 각 patch별로 position embedding을 붙여서 transformer에 넣는다. (idea는 단순함)
'초 간단 논문리뷰' 카테고리의 다른 글
| Self-supervised Learning 이란 | CV, NLP, Speech (0) | 2022.03.29 |
|---|---|
| 초 간단 논문리뷰 | Knowledge Distillation: A Survey (0) | 2021.08.27 |
| 초 간단 논문리뷰 | In-domain GAN Inversion for Real Image Editing (0) | 2021.05.27 |
| 초 간단 논문리뷰 | DeepFM: A Factorization-Machine based Neural Network for CTR Predictio (0) | 2021.04.21 |
| 초 간단 논문리뷰 | DETR, Facebook AI (End-to-End Object Detection with Transformers) (0) | 2021.03.24 |